Exhaustive search
1. Overview
Exhaustive Search will always find the global optimum and recognize it too. That being said, it doesn’t scale (not even beyond toy data sets) and is therefore mostly useless.
2. Brute force
2.1. Algorithm description
The Brute Force algorithm creates and evaluates every possible solution.
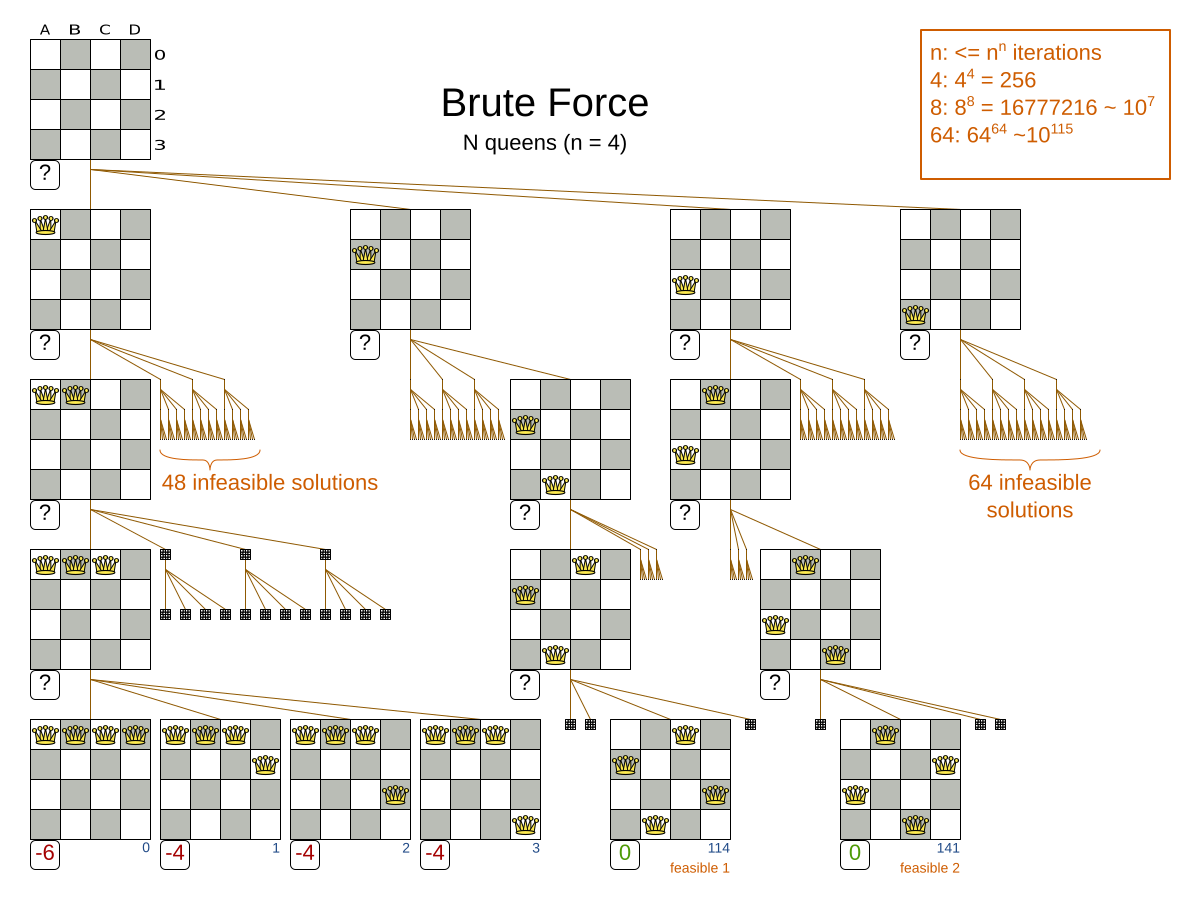
Notice that it creates a search tree that explodes exponentially as the problem size increases, so it hits a scalability wall.
|
Brute Force is mostly unusable for a real-world problem due to time limitations, as shown in scalability of Exhaustive Search. |
2.2. Configuration
Simplest configuration of Brute Force:
<solver xmlns="https://www.optaplanner.org/xsd/solver" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="https://www.optaplanner.org/xsd/solver https://www.optaplanner.org/xsd/solver/solver.xsd">
...
<exhaustiveSearch>
<exhaustiveSearchType>BRUTE_FORCE</exhaustiveSearchType>
</exhaustiveSearch>
</solver>3. Branch and bound
3.1. Algorithm description
Branch And Bound also explores nodes in an exponential search tree, but it investigates more promising nodes first and prunes away worthless nodes.
For each node, Branch And Bound calculates the optimistic bound: the best possible score to which that node can lead to. If the optimistic bound of a node is lower or equal to the global pessimistic bound, then it prunes away that node (including the entire branch of all its subnodes).
|
Academic papers use the term lower bound instead of optimistic bound (and the term upper bound instead of pessimistic bound), because they minimize the score. OptaPy maximizes the score (because it supports combining negative and positive constraints). Therefore, for clarity, it uses different terms, as it would be confusing to use the term lower bound for a bound which is always higher. |
For example: at index 14, it sets the global pessimistic bound to -2.
Because all solutions reachable from the node visited at index 11 will have a score lower or equal to -2 (the node’s optimistic bound), they can be pruned away.
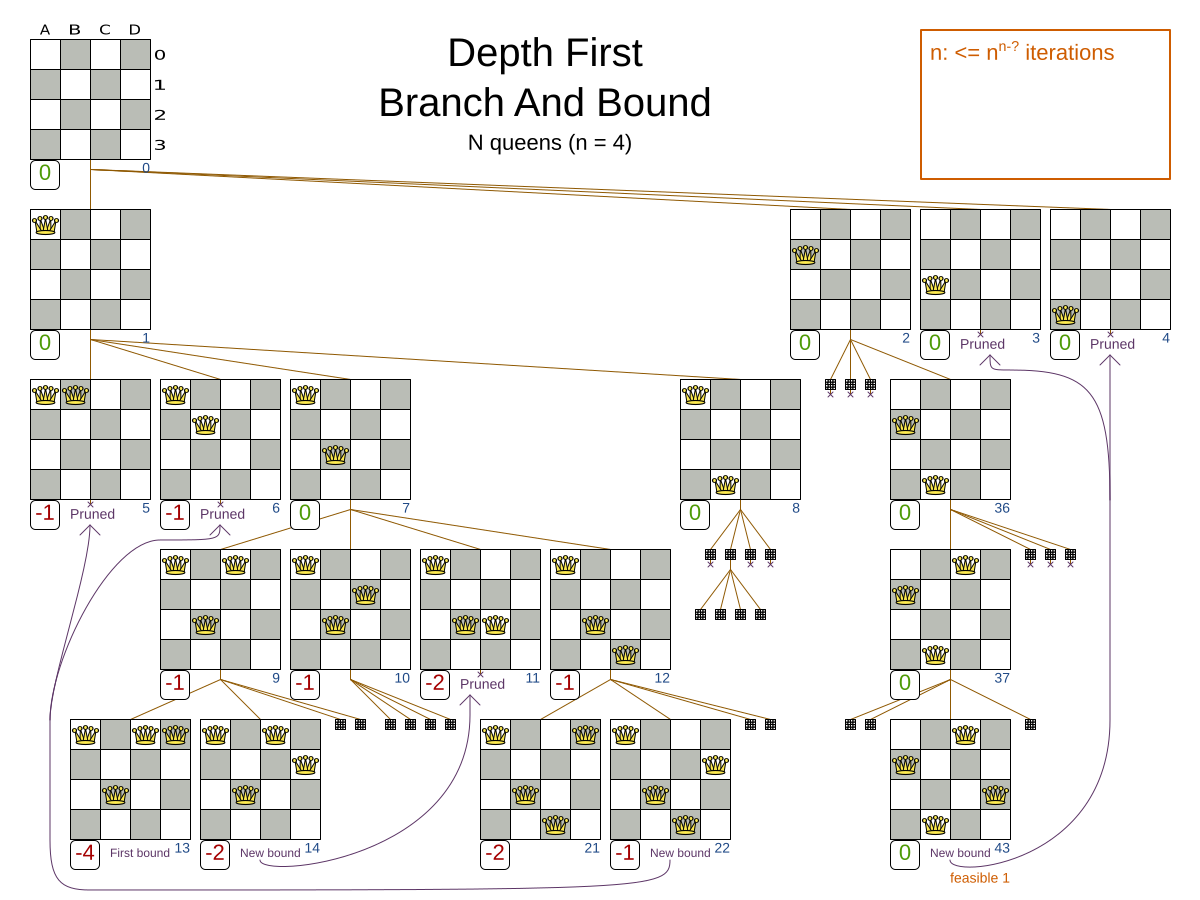
Notice that Branch And Bound (much like Brute Force) creates a search tree that explodes exponentially as the problem size increases. So it hits the same scalability wall, only a little bit later.
|
Branch And Bound is mostly unusable for a real-world problem due to time limitations, as shown in scalability of Exhaustive Search. |
3.2. Configuration
Simplest configuration of Branch And Bound:
<solver xmlns="https://www.optaplanner.org/xsd/solver" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="https://www.optaplanner.org/xsd/solver https://www.optaplanner.org/xsd/solver/solver.xsd">
...
<exhaustiveSearch>
<exhaustiveSearchType>BRANCH_AND_BOUND</exhaustiveSearchType>
</exhaustiveSearch>
</solver>|
For the pruning to work with the default |
Advanced configuration:
<exhaustiveSearch>
<exhaustiveSearchType>BRANCH_AND_BOUND</exhaustiveSearchType>
<nodeExplorationType>DEPTH_FIRST</nodeExplorationType>
<entitySorterManner>DECREASING_DIFFICULTY_IF_AVAILABLE</entitySorterManner>
<valueSorterManner>INCREASING_STRENGTH_IF_AVAILABLE</valueSorterManner>
</exhaustiveSearch>The nodeExplorationType options are:
-
DEPTH_FIRST(default): Explore deeper nodes first (and then a better score and then a better optimistic bound). Deeper nodes (especially leaf nodes) often improve the pessimistic bound. A better pessimistic bound allows pruning more nodes to reduce the search space.<exhaustiveSearch> <exhaustiveSearchType>BRANCH_AND_BOUND</exhaustiveSearchType> <nodeExplorationType>DEPTH_FIRST</nodeExplorationType> </exhaustiveSearch> -
BREADTH_FIRST(not recommended): Explore nodes layer by layer (and then a better score and then a better optimistic bound). Scales terribly in memory (and usually in performance too).<exhaustiveSearch> <exhaustiveSearchType>BRANCH_AND_BOUND</exhaustiveSearchType> <nodeExplorationType>BREADTH_FIRST</nodeExplorationType> </exhaustiveSearch> -
SCORE_FIRST: Explore nodes with a better score first (and then a better optimistic bound and then deeper nodes first). Might scale as terribly asBREADTH_FIRSTin some cases.<exhaustiveSearch> <exhaustiveSearchType>BRANCH_AND_BOUND</exhaustiveSearchType> <nodeExplorationType>SCORE_FIRST</nodeExplorationType> </exhaustiveSearch> -
OPTIMISTIC_BOUND_FIRST: Explore nodes with a better optimistic bound first (and then a better score and then deeper nodes first). Might scale as terribly asBREADTH_FIRSTin some cases.<exhaustiveSearch> <exhaustiveSearchType>BRANCH_AND_BOUND</exhaustiveSearchType> <nodeExplorationType>OPTIMISTIC_BOUND_FIRST</nodeExplorationType> </exhaustiveSearch>
The entitySorterManner options are:
-
DECREASING_DIFFICULTY: Initialize the more difficult planning entities first. This usually increases pruning (and therefore improves scalability). Requires the model to support planning entity difficulty comparison. -
DECREASING_DIFFICULTY_IF_AVAILABLE(default): If the model supports planning entity difficulty comparison, behave likeDECREASING_DIFFICULTY, else likeNONE. -
NONE: Initialize the planning entities in original order.
The valueSorterManner options are:
-
INCREASING_STRENGTH: Evaluate the planning values in increasing strength. Requires the model to support planning value strength comparison. -
INCREASING_STRENGTH_IF_AVAILABLE(default): If the model supports planning value strength comparison, behave likeINCREASING_STRENGTH, else likeNONE. -
DECREASING_STRENGTH: Evaluate the planning values in decreasing strength. Requires the model to support planning value strength comparison. -
DECREASING_STRENGTH_IF_AVAILABLE: If the model supports planning value strength comparison, behave likeDECREASING_STRENGTH, else likeNONE. -
NONE: Try the planning values in original order.
4. Scalability of exhaustive search
Exhaustive Search variants suffer from two big scalability issues:
-
They scale terribly memory wise.
-
They scale horribly performance wise.
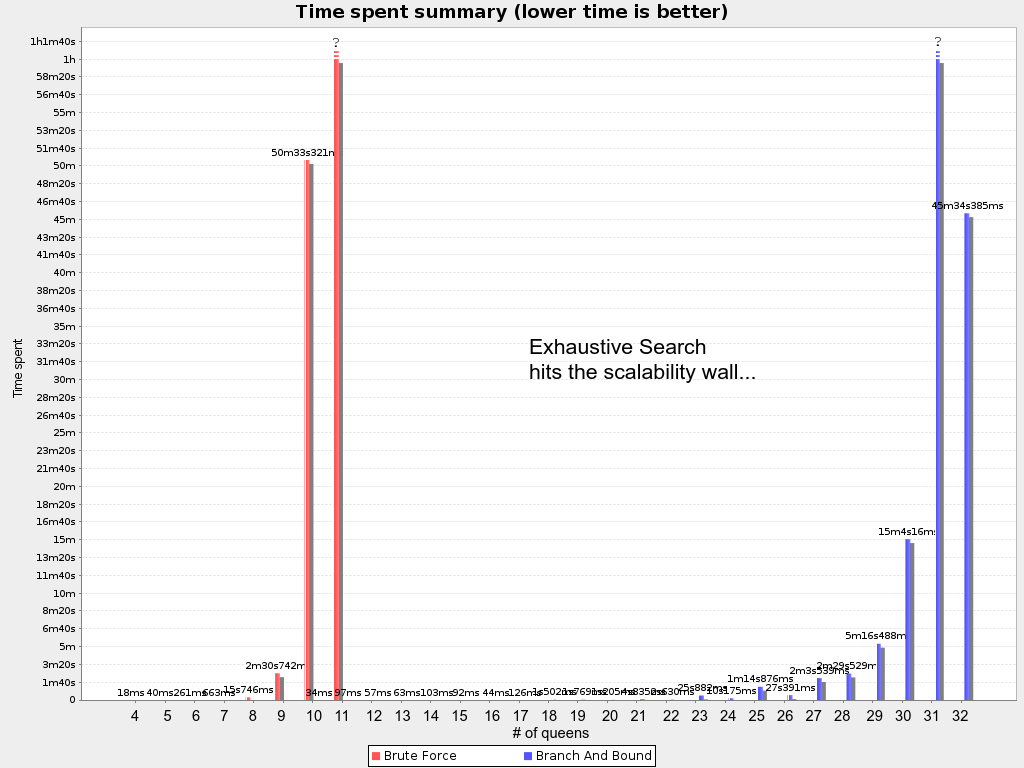
As shown in these time spent graphs, Brute Force and Branch And Bound both hit a performance scalability wall. For example, on N queens it hits wall at a few dozen queens:
In most use cases, such as Cloud Balancing, the wall appears out of thin air:
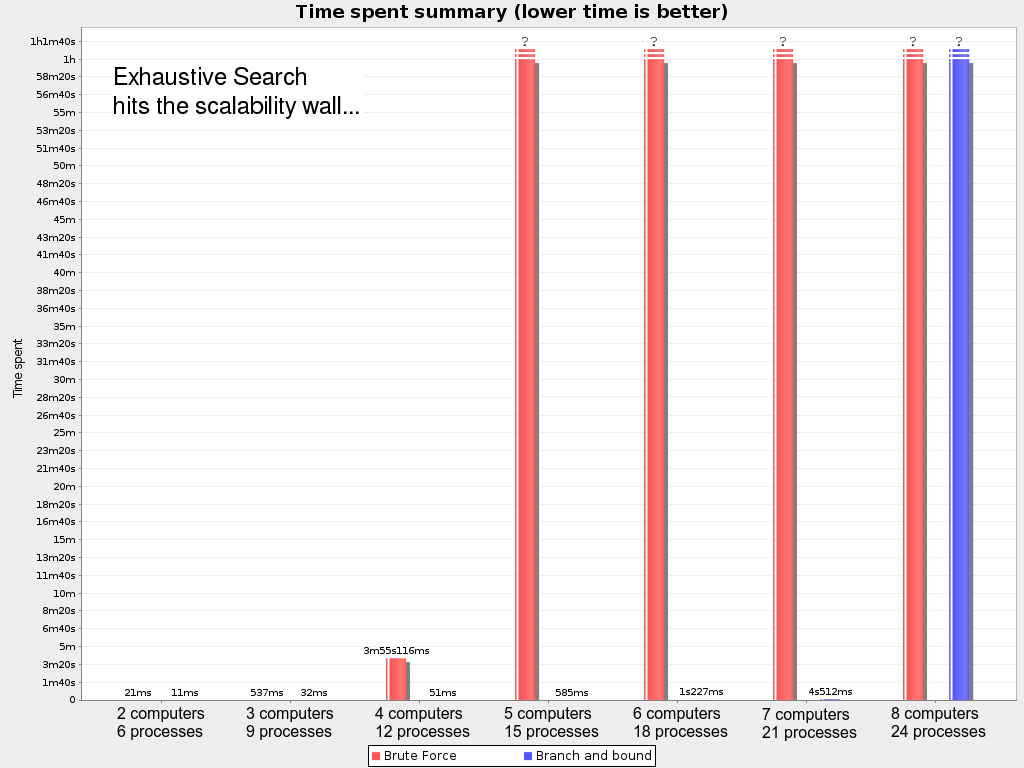
Exhaustive Search hits this wall on small datasets already, so in production these optimizations algorithms are mostly useless. Use Construction Heuristics with Local Search instead: those can handle thousands of queens/computers easily.
|
Throwing hardware at these scalability issues has no noticeable impact. Newer and more hardware are just a drop in the ocean. Moore’s law cannot win against the onslaught of a few more planning entities in the dataset. |