Partitioned search
1. Algorithm description
It is often more efficient to partition large data sets (usually above 5000 planning entities) into smaller pieces and solve them separately. Partition Search is multithreaded, so it provides a performance boost on multi-core machines due to higher CPU utilization. Additionally, even when only using one CPU, it finds an initial solution faster, because the search space sum of a partitioned Construction Heuristic is far less than its non-partitioned variant.
However, partitioning does lead to suboptimal results, even if the pieces are solved optimally, as shown below:
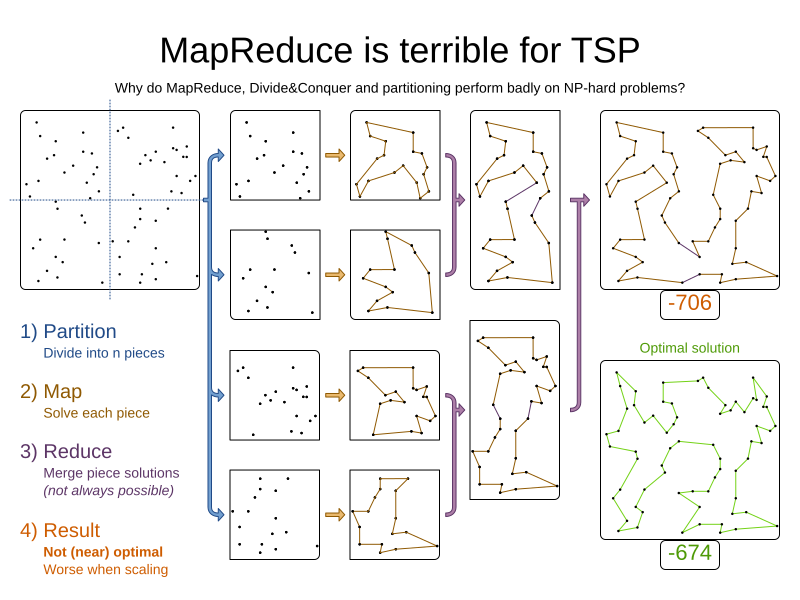
It effectively trades a short term gain in solution quality for long term loss. One way to compensate for this loss, is to run a non-partitioned Local Search after the Partitioned Search phase.
|
Not all use cases can be partitioned. Partitioning only works for use cases where the planning entities and value ranges can be split into n partitions, without any of the constraints crossing boundaries between partitions. |
OptaPy currently does not support partitioned search, but will support it in a future version.